typedefstructcondvar{ semaphore_t sem; // the sem semaphore is used to down the waiting proc, and the signaling proc should up the waiting proc int count; // the number of waiters on condvar monitor_t * owner; // the owner(monitor) of this condvar } condvar_t;
typedefstructmonitor{ semaphore_t mutex; // the mutex lock for going into the routines in monitor, should be initialized to 1 semaphore_t next; // the next semaphore is used to down the signaling proc itself, and the other OR wakeuped waiting proc should wake up the sleeped signaling proc. int next_count; // the number of of sleeped signaling proc condvar_t *cv; // the condvars in monitor } monitor_t;
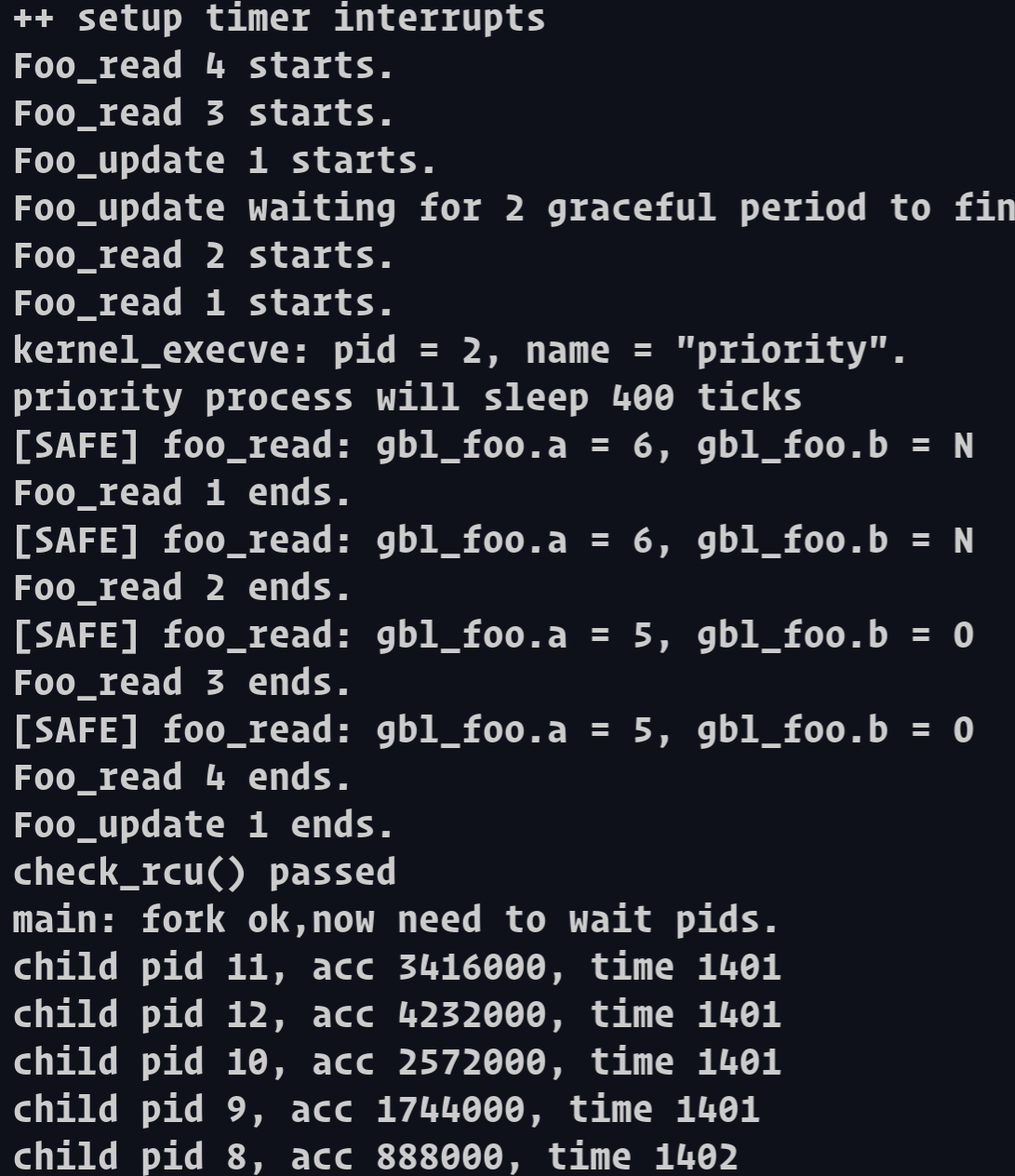
//信号量 staticvoidrcu_read_lock(foo_t* ref){ bool intr_flag; local_intr_save(intr_flag); { if (ref == old_foo_ref) { grace_period_count += 1; } } } //信号量 staticvoidrcu_read_unlock(foo_t* ref){ bool intr_flag; local_intr_save(intr_flag); { if (ref == old_foo_ref) { grace_period_count -= 1; } } } //重置 staticintresync_rcu_trail(){ return (grace_period_count != 0); } //读,老进程就增加"宽限区" staticvoidfoo_read(int id){ cprintf("Foo_read %d starts.\n", id); rcu_read_lock(gbl_foo); // 读取旧值的指针 foo_t* fp = gbl_foo; // If fp == NULL, it means gbl_foo has been deleted (don't care whether it is destroyed) if (fp != NULL) { // Sleep for some time. //这里我不是很清楚为什么要sleep do_sleep(2); cprintf("[SAFE] foo_read: gbl_foo.a = %d, gbl_foo.b = %c\n", fp->a, fp->b); } else { panic("[DANGER] foo_read: attempt to read foo when foo is null."); } rcu_read_unlock(fp); cprintf("Foo_read %d ends.\n", id); } //更新共享资源的位置,写 // Update the gbl_foo to new_fp and free the old_fp. // However, the free process could happen when Line36 is running. // Thus, we need to do the update but delay the destroy of old_foo. // Until all foo_reads exits the critical area. staticvoidfoo_update(int id){ cprintf("Foo_update %d starts.\n", id); // foo_sem is a mutex for gbl_foo down(&(foo_sem)); foo_t* old_fp = gbl_foo; gbl_foo = new_foo_ref; up(&(foo_sem)); cprintf("Foo_update waiting for %d graceful period to finish.\n", grace_period_count); // spin when process left in grace period while (resync_rcu_trail()) schedule(); kfree(old_fp); cprintf("Foo_update %d ends.\n", id); } //测试rcu voidcheck_rcu(){ sem_init(&(foo_sem), 1); old_foo_ref = (foo_t*) kmalloc(sizeof(foo_t)); old_foo_ref->a = 5; old_foo_ref->b = 'O'; new_foo_ref = (foo_t*) kmalloc(sizeof(foo_t)); new_foo_ref->a = 6; new_foo_ref->b = 'N';
gbl_foo = old_foo_ref;
int r1k = kernel_thread(foo_read, (void *)1, 0); int r2k = kernel_thread(foo_read, (void *)2, 0); int w1k = kernel_thread(foo_update, (void *)1, 0); int r3k = kernel_thread(foo_read, (void *)3, 0); int r4k = kernel_thread(foo_read, (void *)4, 0);