ucore-lab2
本文最后更新于:2023年8月29日 下午
参考资料
知识点
连续内存分配

最先匹配就是寻找第一个大于所需空间的空闲块。
最佳匹配找到比n大的最小的那个空闲块,可以减少碎片的尺度。
最差匹配找不小于n的最大空闲分区。可以避免出现太多小碎片,但外部碎片较多,释放慢。
非连续式内存就是常见的段表管理机制。
其他内容建议看Kiprey
ucore_lab2
练习0
合并代码,直接meld然后copy to right就行,lab1修改的文件有:
- kern/debug/kdebug.c
- kern/trap/trap.c
- kern/init/init.c
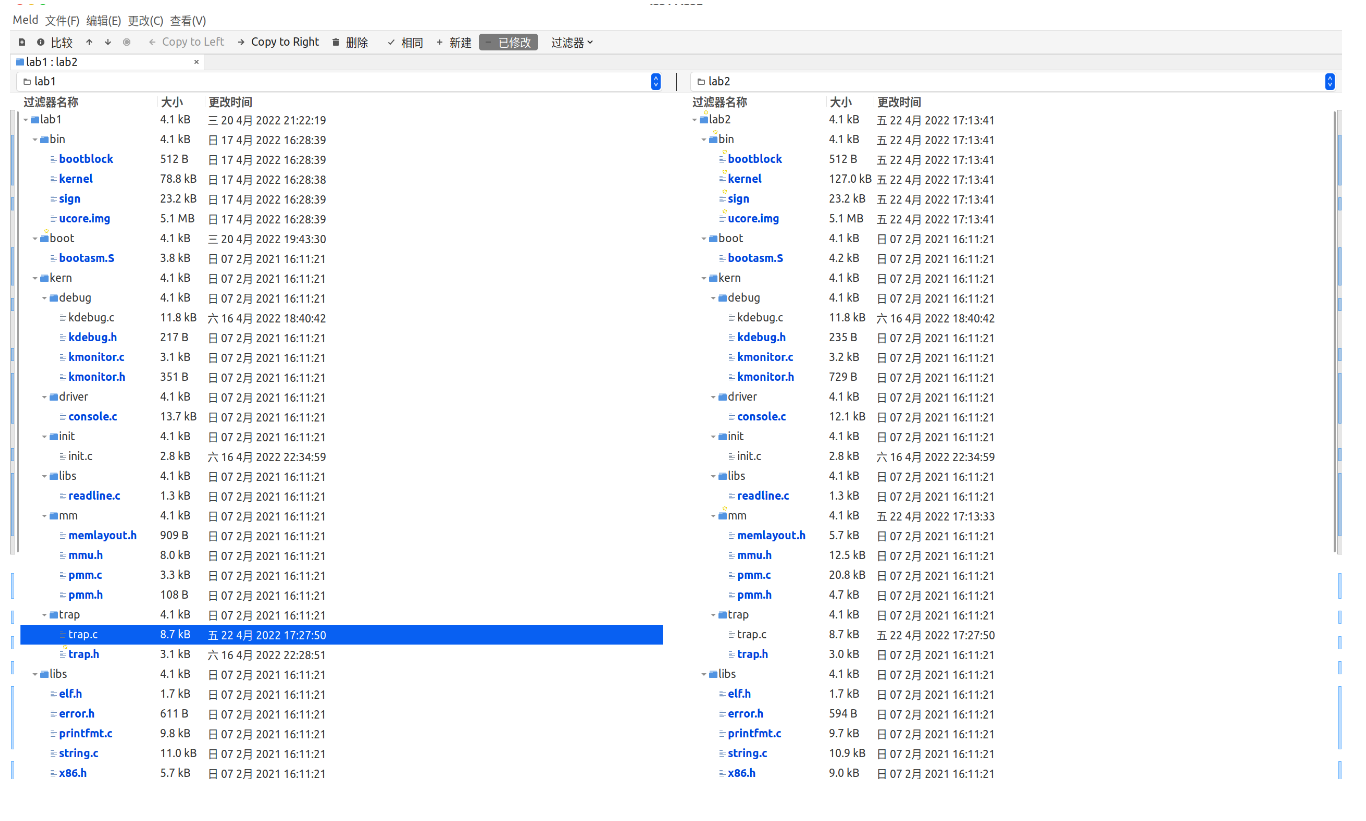
可以看到lab2与lab1有很多文件不同,记得只能修改上述三个文件。
练习1
找到kern/mm/default_pmm.c,按照提示分别查看default_init,default_init_memmap,default_alloc_pages, default_free_pages等相关函数。
首先看 default_init_memmap 函数,这个函数要实现的是对内存块的初始化,通过传入页基址以及大小来插入页,但在最下面一行可以看到:
1 | |
list_add是什么?
可以看到注释:
1 | |
这就有问题了。之前讲过,first-fit算法是寻找第一个满足内存需求的地址空间,通过一个链表来实现这个功能。但list_add函数是把元素加在listelm的后面,只有list_add_before函数是把元素加在listelm的前面,因此我们应该使用list_add_before。具体list实现位于libs/list.h,
list_add:
1 | |
list_add_before:
1 | |
因此可以更改为:
1 | |
接着看 default_alloc_pages 函数,看名字猜测应该是用于分配空间的函数。仔细看一下他的实现,不难发现,程序在分配完空间后仍旧按照原先的顺序排列链表中分配剩余的内存元素,因此我们要更改代码为:
1 | |
而原先的代码是:
1 | |
最后看 default_free_pages 函数,用于释放页。考虑first-fit算法,在释放页的时候应该按照大小顺序插入链表,但该函数里面仍采用了list_add函数,
1 | |
那么我们就需要把最后一句代码修改为:
1 | |
first-fit算法是通过采用链表来实现查找的,实际上可以采用更高效的数据结构比如bst,红黑树这些。
执行 make qemu 得到:
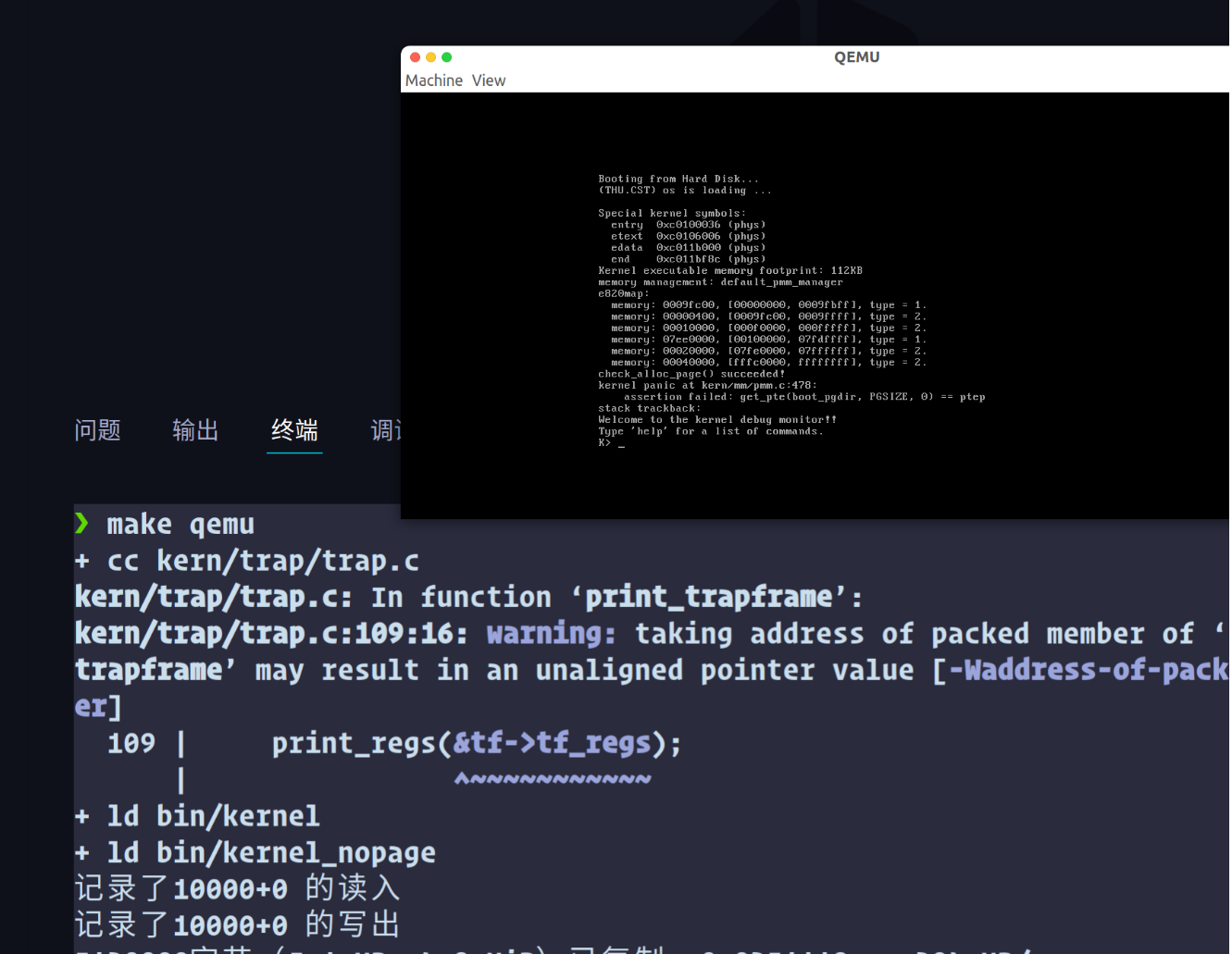
小字部分显示 check_alloc_page() succeeded! 即为成功
练习二
补全get_pte函数,该函数的call graph如下:
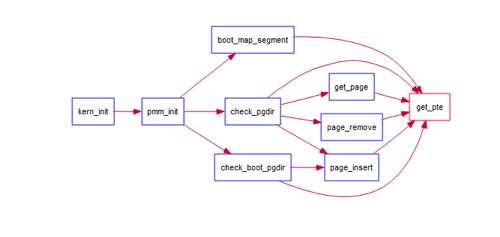
在kern/mm/pmm.c找到get_pte函数,根据注释不难写出:
1 | |
每一个页表项PTE都由一个32位整数来存储数据的,结构从左到右一次是:
| 31-12 | 9-11 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
|---|---|---|---|---|---|---|---|---|---|---|
| offset | avail | MBZ | PS | D | A | PCD | PWT | U | W | P |
- 0 - Present: 表示当前PTE所指向的物理页面是否驻留在内存中,确认物理页是否存在
- 1 - Writeable: 表示是否允许读写,
- 2 - User: 表示该页的访问所需要的特权级。即User(ring 3)是否允许访问,方便ucore进行权限管理
- 3 - PageWriteThough: 表示是否使用write through缓存写策略
- 4 - PageCacheDisable: 表示是否不对该页进行缓存
- 5 - Access: 表示该页是否已被访问过,
- 6 - Dirty: 表示该页是否已被修改,确认数据是否有效
- 7 - PageSize: 表示该页的大小
- 8 - MustBeZero: 该位必须保留为0
- 9-11 - Available: 第9-11这三位并没有被内核或中断所使用,可保留给OS使用。
- 12-31 - Offset: 目标地址的后20位,定位物理页的位置
上面一部分摘抄自
若出现了页访问异常,硬件可以
- 将引发页访问异常的地址将被保存在cr2寄存器中
- 设置错误代码
- 引发Page Fault,将外存的数据换到内存中
- 进行上下文切换,退出中断,返回到中断前的状态
练习三
补全在 kern/mm/pmm.c中的page_remove_pte函数,page_remove_pte的call graph:
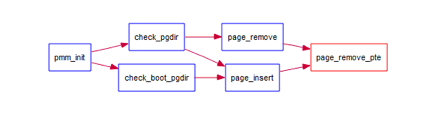
代码补全如下:
1 | |
此时再次执行 make qemu 可以看到:
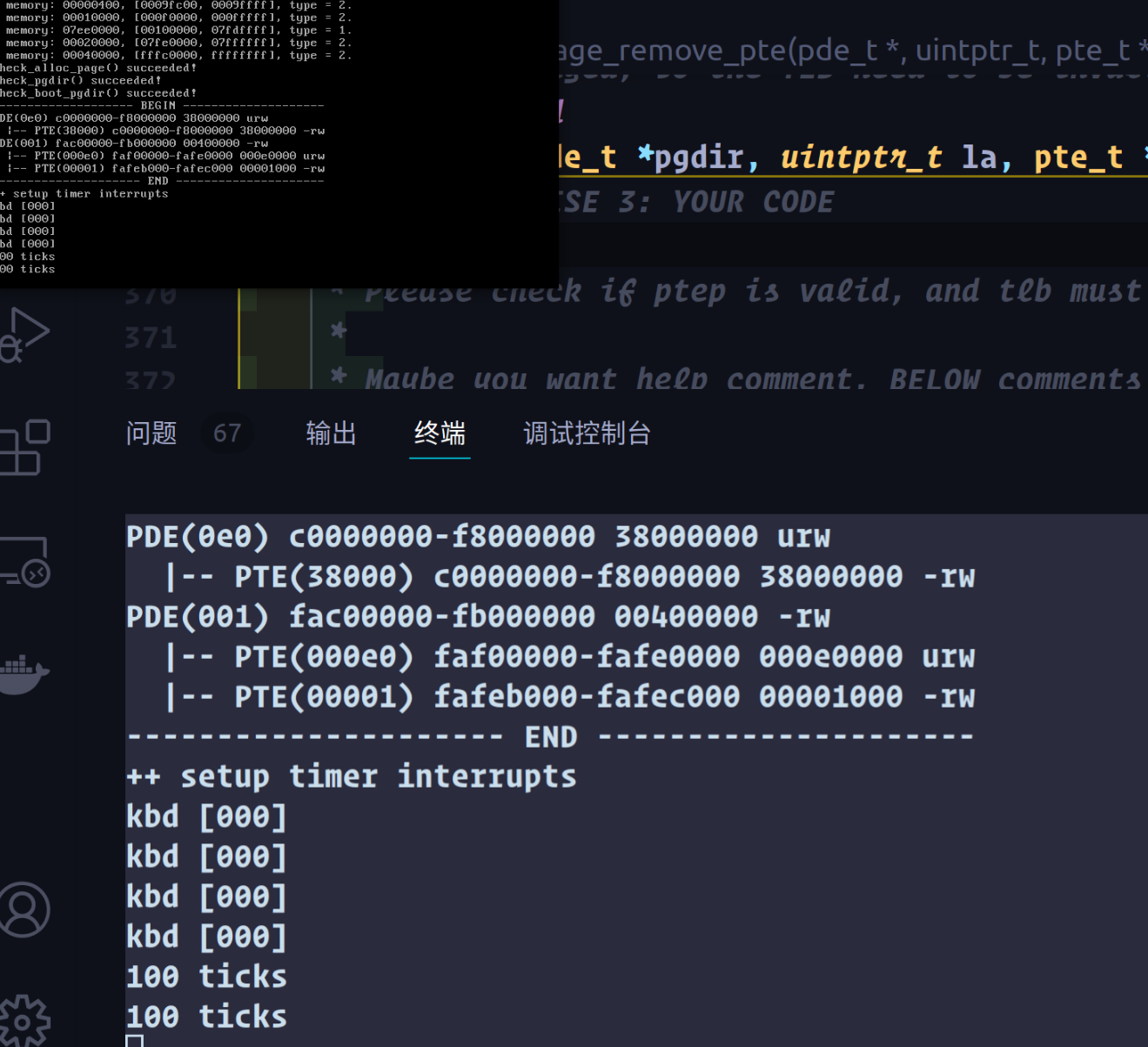
小字显示check_pgdir(),ckeck_boot_pgdir()执行成功,ucore正常执行lab1中完成的功能。
显然,当页目录项或者页表项有效的时候,page数组中的项与其存在对应关系。因为pages数组记载的是物理页的信息,而在段页式存储机制中,页目录项记载页表的信息,页表记载物理页的信息。pages数组记载的数据和页目录项/页表项记载的数据指向的可能是同一个物理页。
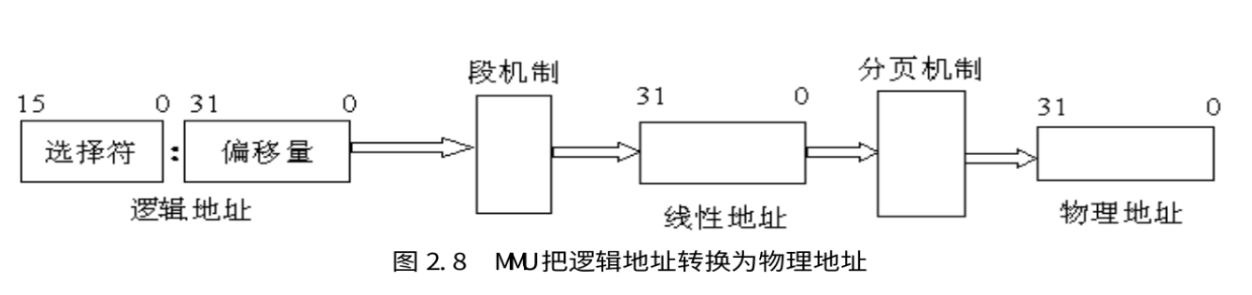
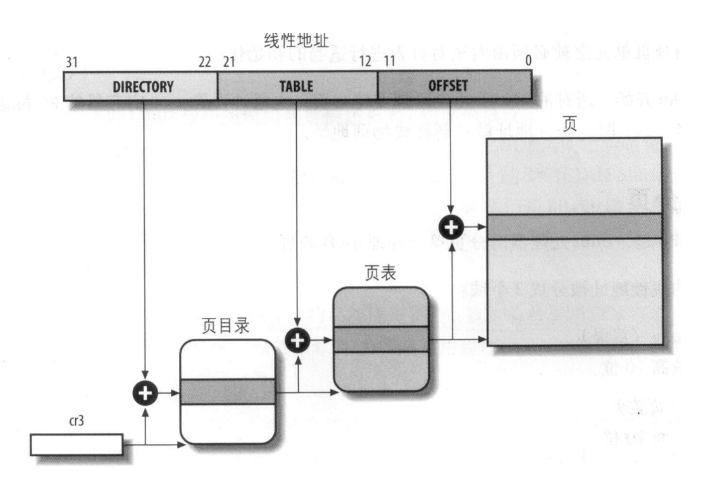
然后lab2提了一个问题,如何使虚拟地址与物理地址相等?
显然,由于我们现在的ucore是通过虚拟地址到物理地址的映射实现的内存管理,如果要取消该映射,我们应该反向查找lab2中的映射方式。首先是更改内核的加载地址为0,在lab2-copy中更改tools/kernel.ld,把内核的加载地址由0xc0100000修改为0x0,之后修改内核偏移地址,在kern/mm/memlayout.h中修改偏移量由0xc00000为0x0,之后关闭页机制即可。在obj/kernel_nopage.asm注释掉即可:
1 | |
重新make qemu,可以看到:
1 | |
程序认为这种读写形式是dangerous的,禁止了我们的读写。而这个raw实际上是原始的一种磁盘镜像格式,是一种稀疏文件。
challenge 1
我的建议是仔细阅读文档里给的链接:coolshell
伙伴分配的实质就是一种特殊的“分离适配”,即将内存按2的幂进行划分,相当于分离出若干个块大小一致的空闲链表,搜索该链表并给出同需求最佳匹配的大小。其优点是快速搜索合并(O(logN)时间复杂度)以及低外部碎片(最佳适配best-fit);其缺点是内部碎片,因为按2的幂划分块,如果碰上66单位大小,那么必须划分128单位大小的块。但若需求本身就按2的幂分配,比如可以先分配若干个内存池,在其基础上进一步细分就很有吸引力了。
要实现一个伙伴算法,且这个算法中对可用存储空间的大小划分必须是二次幂,这很容易令人想到二叉树。我们来一步一步实现。
首先是要有一个函数能够把数字转为最接近该数字的二次幂的函数。
1 | |
类比于kern/mm中对内存的管理,我们先要初始化我们的init_memmap,由于我们要按照二次幂的大小来分割我们的空间,我们可以得到这样一个内存分布,
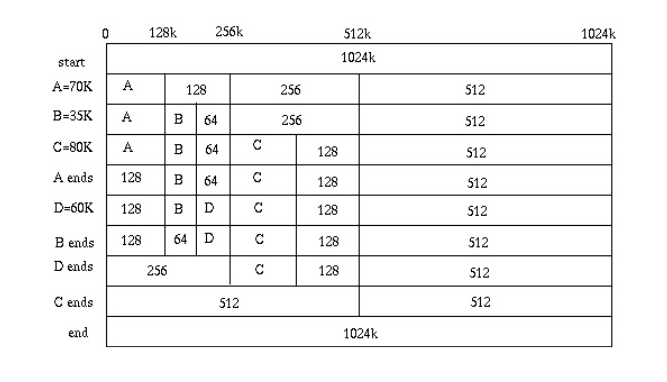
假设一个内存块有1024k,当A需要70k的时候,我们从1024开始寻找一个大小为二次幂x在除以2后小于70k的内存块,即找到第一个能够刚好容纳下A的内存块。之后加入b,c,d这三个块,释放内存时合并相邻的块即可。
在coolshell中提到了这样一种实现方法,通过一个二叉树监控管理内存,根节点监控x大小的块,第一层节点监控x/2大小的块,依次类推。具体实现细节请自行查看coolshell.
实际上我们在实现的时候可以不采用coolshell提到的struct,而是直接通过算法去抽象的完成这样一个树。
Kiprey就是采用双向链表实现,内存上的开销会比较小,但在双向链表中难以确定块之间的合并操作。ZebornDuan采用了二叉树实现,我决定参考他的代码写一写。
buddy.h仿照default_pmm.h即可,
1 | |
主要是实现buddy.c,建议参考github
这里引用一下:
特别地,假设Buddy System需要管理2h个物理页面,即二叉树的叶节点总共有2h个,则二叉树的结点总数为2(h+1)-1个,简单起见,这里直接算作2(h+1)个。而每个结点需要一个4字节整数来记录其可用空间,因此维护二叉树所需要的总的存储空间为2(h+3)B。一个页面的大小为4KB即212B,因此需要的物理页数为2(h-9)页。内存成页分配,最终消耗的页数为max{1,2(h-9)}。
如果需要管理的物理页数不大于512页,则拿出其中一页用来维护信息,剩下的页数取不大于它的最大2的整数幂页来构成二叉树。如果需要管理的物理页数大于512页,设为t页,则需要求解不等式 2^(h-9) + 2^h <= t,从而确定组织成多大规模的二叉树。而这样势必会造成一部分物理页既没有用来维护信息,也无法被分配,从而被浪费的情况。为了避免这种情况,可以在当存在物理页冗余的情况下,扩大二叉树的规模,这样即增大了可以被分配的物理页,也需要分配更多的页来维护信息,但一般情况下,这种方式实际获得的能够分配的物理页数是增加的,因为增加一页用来维护信息就最多可以获得512页用来分配。为了尽可能的使所有的物理页都得到利用,对于t>512的情况,直接建立最大规模的二叉树,即其叶结点数不超过t其为最大的2的整数幂,不妨设为2^h,并为这些页面分配维护其信息的页。如果总页数再加倍维护页的情况下仍然有冗余,则使维护页和分配页同时加倍。对于二叉树中无法对应到物理页中的一部分结点,可以视为其已经被分配,且永远不会被释放从,让除维护页以外所有的页面都有可能被分配出去。
还是太菜了,也没时间,就给佬的代码写了点注释,看懂了佬的代码。
还是太菜了。
challenge2不做
参考资料少,slub不太了解,科研太忙,期中考试要复习,以后有空不可能的在做。
本文作者: Heeler-Deer
本文链接: https://heeler-deer.top/posts/28411/
版权声明: 本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!